Dockerでプライベートネットワークを構築してネットワークを学んでみた
2025年3月26日 • じゅげむ

環境
ホストOSはWindows 10。
Dockerのバージョンは27.5.1。
用語説明
ここでは登場する用語について、簡潔に説明する。
- NIC
コンピュータとネットワークを接続するためのハードウェアデバイス。データの送受信を物理的に行う役割を担う。 - ルーター
異なるネットワーク間を繋ぎ、データを適切なネットワークへ流す中継機器。 - グローバルネットワーク(WAN)
インターネットのこと。接続された機器は世界中に公開されている。 - プライベートネットワーク(LAN)
グローバルネットワークからは閲覧できないネットワークのこと。あなたのご家庭のネットワークもこれ。 - IPアドレス
ネットワーク内の機器に与えられる一意の識別番号。WAN上で用いられるグローバルIPアドレスとLAN内でのみ用いられるプライベートIPアドレスに分かれる。
より細かな説明は実際にネットワークを扱う中で行っていく。
実際にネットワークを構築してみよう
では実際にDockerを用いてネットワークがどんなものか触れていきたいと思う。
最終的には図のようなネットワークになる。
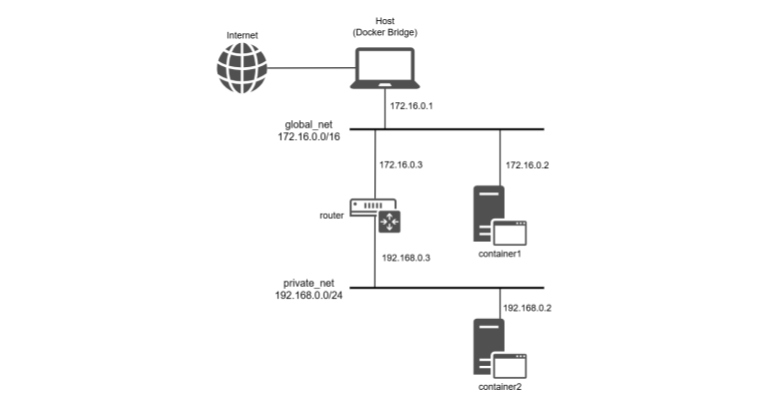
global_netも厳密にはLANであるが、ここではWANとして扱う。
ネットワーク内でコンテナ間の通信を行う
まずネットワークを作成する。
$ docker network create original_net実際にoriginal_netというネットワークが作成されていることが確認できる。
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
24d7e786ae9a bridge bridge local
f356d7837e08 host host local
d68455ef1eb2 none null local
e9115a7d61a9 original_net bridge local次に作成したネットワークにコンテナを追加してみよう。
$ docker run -d --name container1 --network original_net alpine sleep infinity
$ docker run -d --name container2 --network original_net alpine sleep infinityネットワーク内にコンテナが含まれていることがわかる。
$ docker network inspect original_net
[
{
"Name": "original_net",
...(略)...
"Containers": {
"4df7e11ea8554d948f9516ea670fddbc1daf73fea3c238177ae41610ec0c594f": {
"Name": "container2",
"EndpointID": "0cc2a00eccfaaa1bf477a21362f512c5734d382cc5813f87b89bd0f41752db15",
"MacAddress": "02:42:ac:12:00:03",
"IPv4Address": "172.18.0.3/16",
"IPv6Address": ""
},
"e39b8e70bc02388b9a7cae7fab3a9e77d1791e5e2c7a75fe26def1f4e227627f": {
"Name": "container1",
"EndpointID": "80c03ab0db0238b68b4cfe75aa348d850ecdffd11beda66f5979536df8ebb5a2",
"MacAddress": "02:42:ac:12:00:02",
"IPv4Address": "172.18.0.2/16",
"IPv6Address": ""
}
},
"Options": {},
"Labels": {}
}
図だと下のような感じ。
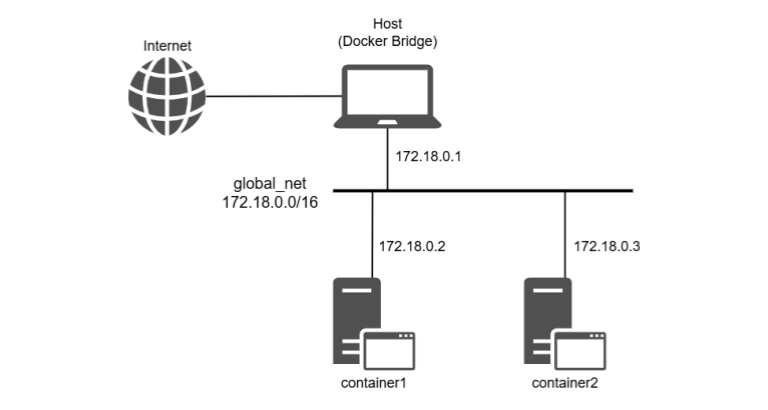
ということで実際にコンテナ間の通信が可能かどうか見てみよう。
container1からcontainer2に向けてpingを飛ばしてみる。
$ docker exec container1 ping -c 4 172.18.0.3
PING 172.18.0.3 (172.18.0.3): 56 data bytes
64 bytes from 172.18.0.3: seq=0 ttl=64 time=0.118 ms
64 bytes from 172.18.0.3: seq=1 ttl=64 time=0.317 ms
64 bytes from 172.18.0.3: seq=2 ttl=64 time=0.322 ms
64 bytes from 172.18.0.3: seq=3 ttl=64 time=0.374 ms
--- 172.18.0.3 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.118/0.282/0.374 ms
問題なく通信できているようだ。
ここまでは序の口、というかDockerのコマンドを叩いただけ()
次からが本題。
プライベートネットワークを構築しよう
先ほどと同じように、2つのネットワークを作成する。
# WANの作成
$ docker network create --subnet=172.16.0.0/16 global_net
# LANの作成
$ docker network create --subnet=192.168.0.0/24 private_netそれぞれのネットワーク内にコンテナを1つずつ作成する。
$ docker run -d --name container1 --cap-add=NET_ADMIN --network global_net alpine sleep infinity
$ docker run -d --name container2 --cap-add=NET_ADMIN --network private_net alpine sleep infinityここでcontainer2に対して以下の操作を行っておく。
$ docker exec container2 route del default詳しいことは後述するが、これによりprivate_netはインターネットに繋がらなくなる。
$ docker exec container2 ping -c 4 8.8.8.8
PING 8.8.8.8 (8.8.8.8): 56 data bytes
ping: sendto: Network unreachableここでは8.8.8.8(google.com)にpingを飛ばしているが、container1(172.16.0.2)にpingを飛ばしても同様に繋がらないようになっている。
これでプライベートネットワークの構築が完了となる。
しかし、実際どうだろうか。
私たちが自宅で普段使用するネットワーク環境もプライベートネットワークであるが、インターネットに接続することができる。
ここまでの工程でプライベートネットワークを構築できたものの、インターネットに接続できない状態では何かと不便である。
ということで、次は作成したprivate_netをglobal_netと通信できるようにしてみよう。
プライベートネットワークをWANに繋ごう
まず、ルーターの役目となるコンテナ(router)を作成する。
作成したrouterはglobal_net、private_net両方に繋げておく。
# global_netに接続する形でルーターコンテナを作成
$ docker run -d --name router --cap-add=NET_ADMIN --network global_net alpine sleep infinity
# 作成したルーターコンテナをprivate_netにも接続する
$ docker network connect private_net routerrouterの中に入ってifconfigのeth0とeth1を見ることで両方のネットワークに属していることがわかる。
$ docker exec router ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:10:00:03
inet addr:172.16.0.3 Bcast:172.16.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:7 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:746 (746.0 B) TX bytes:0 (0.0 B)
eth1 Link encap:Ethernet HWaddr 02:42:C0:A8:00:03
inet addr:192.168.0.3 Bcast:192.168.0.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:7 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:746 (746.0 B) TX bytes:0 (0.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)ここまで作成したコンテナについて、IPアドレスは次のような感じになった。
- container1
172.16.0.2 - container2
192.168.0.2 - router(global_net側)
172.16.0.3 - router(private_net側)
192.168.0.3
ネットワークを中継するrouterを作成した訳だが、ここではまだcontainer2からcontainer1へは繋がらない。
$ docker exec container2 ping -c 4 172.16.0.2
PING 172.16.0.2 (172.16.0.2): 56 data bytes
ping: sendto: Network unreachable実はパケットが宛先のIPアドレスへ送り出される際、ルーティングテーブルというものが参照される。
ルーティングテーブルには宛先ネットワークへ到達するにはどの機器が中継してくれるのかについて記されている。
ルーティングテーブルの例を見てみよう。
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 172.18.0.1 0.0.0.0 UG 0 0 0 eth0
172.18.0.0 * 255.255.0.0 U 0 0 0 eth0必要なもののみ各列の説明を載っけておく。
Destination | 宛先ネットワーク |
Gateway | 中継機器 |
Iface | 宛先へ送信する際に使用されるNIC |
Genmaskはサブネットマスクを表す。
重要だけどこの記事だと他で登場することはないので今回はスルーする。
実際にcontainer2のルーティングテーブルを見てみよう。
ルーティングテーブルはrouteコマンドで表示できる。
まず2列目から見ていこう。
Destination Gateway Genmask Flags Metric Ref Use Iface
172.18.0.0 * 255.255.0.0 U 0 0 0 eth0真っ先に意味不明な記述が目に飛び込んでくると思う。
「Gatewayの*ってなに?」
Gatewayの列に*が表示されていればそれは、「172.18.0.0へは中継を介さなくても直接到達可能だよ」ということを表す。
宛先は送信元と同じネットワーク内にあるよということだ。
次に1行目の方を見ていこう。
Destination Gateway Genmask Flags Metric Ref Use Iface
default 172.18.0.1 0.0.0.0 UG 0 0 0 eth0destinationにdefaultとある。
これは、ルーティングテーブル内に記載の無い宛先に対して割り当てられるルートである。
2行目のように特に設定を設けない場合のデフォルトで割り当てられるルートなのでデフォルトルートと呼ばれたりする。
2行目では今度はGatewayにIPアドレスが表示されている。
このIPアドレスの機器が宛先への中継機器であり、次にパケットが渡される機器である。
デフォルトルートのゲートウェイなのでデフォルトゲートウェイと呼ばれる。
つまりこのルーティングテーブルによるルーティングは以下のようになる。
- ネットワーク外への通信はeth0を用いて172.18.0.1に送られる。
- 172.18.0.0への通信はeth0を用いてゲートウェイを介さず直接行われる。
DestinationのdefaultやGatewayの*は環境によっては0.0.0.0と表示されることもある。
ルーティングテーブルについて理解したところでcontainer2のルーティングテーブルを確認してみよう。
以下がcontainer2のルーティングテーブルである。
$ docker exec container2 route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.0.0 * 255.255.255.0 U 0 0 0 eth0192.168.0.0という、container2の存在するネットワーク内への通信ルートが存在するだけである。
ここにデフォルトゲートウェイを追加するため以下のコマンドを実行する。
$ docker exec container2 ip route add default via 192.168.0.3 dev eth0これでcontainer2のルーティングテーブルにデフォルトゲートウェイが追加された。
$ docker exec container2 route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default router.private_ 0.0.0.0 UG 0 0 0 eth0
192.168.0.0 * 255.255.255.0 U 0 0 0 eth0これでcontainer1との通信が可能になったかというとまだそういう訳ではない。
$ docker exec container2 ping -c 4 172.16.0.2
PING 172.16.0.2 (172.16.0.2): 56 data bytes
--- 172.16.0.2 ping statistics ---
4 packets transmitted, 0 packets received, 100% packet lossただ先ほどとは表記が変わっている。
ここでターミナルをもう一つ開き、container1にtcpdumpというパケットキャプチャツールをインストールして流れてくるパケットを確認してみよう。
今回はeth0、global_net側で流れてくるパケットを確認する。
$ docker exec -it container1 sh
/ # apk update
/ # tcpdump -i eth0この状態でcontainer2からcontainer1へ向けて再びpingを飛ばすとcontainer1を操作しているターミナルに以下の内容が表示された。
04:52:29.792643 IP 192.168.0.2 > 19124e906d7d: ICMP echo request, id 61, seq 0, length 64
04:52:29.792660 IP 19124e906d7d > 192.168.0.2: ICMP echo reply, id 61, seq 0, length 64
04:52:29.866873 IP 19124e906d7d.48099 > 192.168.65.7.53: 51869+ PTR? 2.0.168.192.in-addr.arpa. (42)
04:52:30.144574 IP 192.168.65.7.53 > 19124e906d7d.48099: 51869 NXDomain 0/0/0 (42)
04:52:30.146093 IP 19124e906d7d.37540 > 192.168.65.7.53: 19303+ PTR? 7.65.168.192.in-addr.arpa. (43)
04:52:30.169493 IP 192.168.65.7.53 > 19124e906d7d.37540: 19303 NXDomain 0/0/0 (43)
04:52:30.793083 IP 192.168.0.2 > 19124e906d7d: ICMP echo request, id 61, seq 1, length 64
04:52:30.793107 IP 19124e906d7d > 192.168.0.2: ICMP echo reply, id 61, seq 1, length 64
04:52:31.794860 IP 192.168.0.2 > 19124e906d7d: ICMP echo request, id 61, seq 2, length 64
04:52:31.794888 IP 19124e906d7d > 192.168.0.2: ICMP echo reply, id 61, seq 2, length 64
04:52:32.795494 IP 192.168.0.2 > 19124e906d7d: ICMP echo request, id 61, seq 3, length 64
04:52:32.795532 IP 19124e906d7d > 192.168.0.2: ICMP echo reply, id 61, seq 3, length 64ICMP echo requestに対してcontainer1(多分19124e906d7d?)からcontainer2(192.168.0.2)に向けてしっかり返答をしていることがわかる。
container1は返答をしているにも関わらずなぜcontainer2に届かないのか。
このパケットがどこに向かっているかはcontainer1のルーティングテーブルを見ればよい。
$ docker exec container1 route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 172.16.0.1 0.0.0.0 UG 0 0 0 eth0
172.16.0.0 * 255.255.0.0 U 0 0 0 eth0ルーティングテーブルを見たところ今度はデフォルトゲートウェイが存在する。
container2へのパケットはまずこの172.16.0.1に飛ばされる。
172.16.0.1というのはDockerでネットワークを作成した際にDocker側が自動で作成した仮想の機器であり、仮想ブリッジと呼ばれている。
仮想ブリッジのおかげでDocker内のコンテナを実際のインターネットに繋げることができる。最初にcontainer2をインターネットから切断するために打ったコマンドは、仮想ブリッジをデフォルトゲートウェイから削除する操作である。
$ docker exec container2 route del defaultcontainer2へのパケットはまず仮想ブリッジに飛ばされる。
ところが現在のネットワークの全体図を見てほしい。
global_netとprivate_netを繋いでいるのは実際にはrouterであり、仮想ブリッジはprivate_netには繋がっていない。
仮想ブリッジはprivate_netに対するルートを持たないので、container2へ向かうはずのパケットをホストOSを飛び出し実際のインターネット上へと送り出し、パケットはやがて破棄される。
ではそうならないようにcontainer2へのルートをcontainer1のルーティングテーブルに追加すれば良いのかというとそういう訳でもない。
なぜならcontainer2のIPアドレスはプライベートIPアドレスであり、WAN上には存在できない。
もし追加しようものならcontainer2もWANの一部ということになってしまう。
WAN上には存在できないIPアドレスがWANの一部になる、つまり不可能ということ。
ではどういった方法がLANとWANの通信を可能にするのか。
ここでNATという技術を使う。
NATとは
NATとは送信元のプライベートIPアドレスをルーターのグローバルIPアドレスで置き換える技術、仕組みである。
NATによりパケットを受け取った機器はルーターに送り返すことができ、ルーターは受け取った通信をプライベートネットワーク内の機器に伝えることができる。
では実際にNATをrouterに設定していく。
ChatGPTによると以下のコマンドでできるらしい。
$ docker exec -it router sh
/ # apk update
/ # apk add iptables
/ # iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADEiptablesについても調べてみたけど奥が深そうだったので一旦ChatGPTの言う通りにしておく。
追加した設定は以下で確認できる。
/ # iptables -t nat -v -L POSTROUTING
Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
30 2068 DOCKER_POSTROUTING all -- any any anywhere 127.0.0.11
21 1503 MASQUERADE all -- any eth0 anywhere anywhereこれでcontainer2からcontainer1にpingを飛ばしてみると
$ docker exec container2 ping -c 4 172.16.0.2
PING 172.16.0.2 (172.16.0.2): 56 data bytes
64 bytes from 172.16.0.2: seq=0 ttl=63 time=0.344 ms
64 bytes from 172.16.0.2: seq=1 ttl=63 time=0.357 ms
64 bytes from 172.16.0.2: seq=2 ttl=63 time=1.953 ms
64 bytes from 172.16.0.2: seq=3 ttl=63 time=0.716 ms
--- 172.16.0.2 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.344/0.842/1.953 ms繋がった!
まずrouterのeth1に届き、
/ # tcpdump -n -i eth1
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth1, link-type EN10MB (Ethernet), snapshot length 262144 bytes
05:19:46.984292 IP 192.168.0.2 > 172.16.0.2: ICMP echo request, id 79, seq 0, length 64
05:19:46.984394 IP 172.16.0.2 > 192.168.0.2: ICMP echo reply, id 79, seq 0, length 64
05:19:47.984592 IP 192.168.0.2 > 172.16.0.2: ICMP echo request, id 79, seq 1, length 64
05:19:47.984622 IP 172.16.0.2 > 192.168.0.2: ICMP echo reply, id 79, seq 1, length 64
05:19:48.985750 IP 192.168.0.2 > 172.16.0.2: ICMP echo request, id 79, seq 2, length 64
05:19:48.985871 IP 172.16.0.2 > 192.168.0.2: ICMP echo reply, id 79, seq 2, length 64
05:19:49.986709 IP 192.168.0.2 > 172.16.0.2: ICMP echo request, id 79, seq 3, length 64
05:19:49.986799 IP 172.16.0.2 > 192.168.0.2: ICMP echo reply, id 79, seq 3, length 64routerのeth0側から発信されている。
/ # tcpdump -n -i eth0
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
05:19:46.984310 IP 172.16.0.3 > 172.16.0.2: ICMP echo request, id 79, seq 0, length 64
05:19:46.984389 IP 172.16.0.2 > 172.16.0.3: ICMP echo reply, id 79, seq 0, length 64
05:19:47.984601 IP 172.16.0.3 > 172.16.0.2: ICMP echo request, id 79, seq 1, length 64
05:19:47.984620 IP 172.16.0.2 > 172.16.0.3: ICMP echo reply, id 79, seq 1, length 64
05:19:48.985787 IP 172.16.0.3 > 172.16.0.2: ICMP echo request, id 79, seq 2, length 64
05:19:48.985861 IP 172.16.0.2 > 172.16.0.3: ICMP echo reply, id 79, seq 2, length 64
05:19:49.986732 IP 172.16.0.3 > 172.16.0.2: ICMP echo request, id 79, seq 3, length 64
05:19:49.986791 IP 172.16.0.2 > 172.16.0.3: ICMP echo reply, id 79, seq 3, length 64eth0から発信される際、送信元がrouterのグローバルIPアドレスに置き換えられている。
05:19:46.984310 IP 172.16.0.3 > 172.16.0.2: ICMP echo request, id 79, seq 0, length 64container1にも届いている。
/ # tcpdump -n -i eth0
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
05:19:46.984324 IP 172.16.0.3 > 172.16.0.2: ICMP echo request, id 79, seq 0, length 64
05:19:46.984381 IP 172.16.0.2 > 172.16.0.3: ICMP echo reply, id 79, seq 0, length 64
05:19:47.984607 IP 172.16.0.3 > 172.16.0.2: ICMP echo request, id 79, seq 1, length 64
05:19:47.984617 IP 172.16.0.2 > 172.16.0.3: ICMP echo reply, id 79, seq 1, length 64
05:19:48.985811 IP 172.16.0.3 > 172.16.0.2: ICMP echo request, id 79, seq 2, length 64
05:19:48.985846 IP 172.16.0.2 > 172.16.0.3: ICMP echo reply, id 79, seq 2, length 64
05:19:49.986753 IP 172.16.0.3 > 172.16.0.2: ICMP echo request, id 79, seq 3, length 64
05:19:49.986779 IP 172.16.0.2 > 172.16.0.3: ICMP echo reply, id 79, seq 3, length 64container2からgoogleにpingを飛ばすと返してくれる。
$ docker exec container2 ping -c 4 8.8.8.8
PING 8.8.8.8 (8.8.8.8): 56 data bytes
64 bytes from 8.8.8.8: seq=0 ttl=62 time=16.494 ms
64 bytes from 8.8.8.8: seq=1 ttl=62 time=11.871 ms
64 bytes from 8.8.8.8: seq=2 ttl=62 time=16.903 ms
64 bytes from 8.8.8.8: seq=3 ttl=62 time=12.257 ms
--- 8.8.8.8 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 11.871/14.381/16.903 msこれでprivate_netをWANに接続できた!
ただもう少し設定を加えておこう。
global_netからprivate_netへの新規接続は通さないようにしておく。
コマンドは以下の通り。例の如くChatGPTに全任せ。ポリシーとか何とか使う方が綺麗っぽいけどまた別の機会に書こうと思う。
$ iptables -A FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT
# LAN側(eth1)からWAN側(eth0)への通信は許可
$ iptables -A FORWARD -i eth1 -o eth0 -j ACCEPT
# WAN側(eth0)からLAN側(eth1)への新規接続は拒否
$ iptables -A FORWARD -i eth0 -o eth1 -j DROP設定できているか確認。
/ # iptables -v -L
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT all -- any any anywhere anywhere state RELATED,ESTABLISHED
0 0 ACCEPT all -- eth1 eth0 anywhere anywhere
0 0 DROP all -- eth0 eth1 anywhere anywhere
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
/ # iptables -t nat -v -L
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
31 2137 DOCKER_OUTPUT all -- any any anywhere 127.0.0.11
Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
31 2137 DOCKER_POSTROUTING all -- any any anywhere 127.0.0.11
22 1572 MASQUERADE all -- any eth0 anywhere anywhere
Chain DOCKER_OUTPUT (1 references)
pkts bytes target prot opt in out source destination
0 0 DNAT tcp -- any any anywhere 127.0.0.11 tcp dpt:domain to:127.0.0.11:46813
31 2137 DNAT udp -- any any anywhere 127.0.0.11 udp dpt:domain to:127.0.0.11:43522
Chain DOCKER_POSTROUTING (1 references)
pkts bytes target prot opt in out source destination
0 0 SNAT tcp -- any any 127.0.0.11 anywhere tcp spt:46813 to::53
0 0 SNAT udp -- any any 127.0.0.11 anywhere udp spt:43522 to::53試しにcontainer1にprivate_netへのルートを設定してpingを飛ばしてみる。
$ docker exec container1 ip route add 192.168.0.0/24 via 172.16.0.3 dev eth0
$ docker exec container1 ping -c 4 192.168.0.2
PING 192.168.0.2 (192.168.0.2): 56 data bytes
--- 192.168.0.2 ping statistics ---
4 packets transmitted, 0 packets received, 100% packet lossrouterのeth0には届いているが
/ # tcpdump -n -i eth0
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
06:47:59.068680 IP 172.16.0.2 > 192.168.0.2: ICMP echo request, id 90, seq 0, length 64
06:48:00.068804 IP 172.16.0.2 > 192.168.0.2: ICMP echo request, id 90, seq 1, length 64
06:48:01.069885 IP 172.16.0.2 > 192.168.0.2: ICMP echo request, id 90, seq 2, length 64
06:48:02.070408 IP 172.16.0.2 > 192.168.0.2: ICMP echo request, id 90, seq 3, length 64eth1からは発信されていないことがわかる。
/ # tcpdump -n -i eth1
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth1, link-type EN10MB (Ethernet), snapshot length 262144 bytesこの状態でもprivate_netからglobal_netへの通信は変わらず行える。確認してみてほしい
最後に今回作成したネットワークのcompose.ymlを作成しておく。
version: "3.8"
services:
router:
image: alpine:3.16
container_name: router
cap_add:
- NET_ADMIN
command: >
sh -c "apk add --no-cache iptables &&
iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE &&
iptables -A FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT &&
iptables -A FORWARD -i eth1 -o eth0 -j ACCEPT &&
iptables -A FORWARD -i eth0 -o eth1 -j DROP &&
sleep infinity"
networks:
global_net:
ipv4_address: 172.16.0.254
private_net:
ipv4_address: 192.168.0.254
container1:
image: alpine:3.16
container_name: container1
command: sleep infinity
networks:
global_net: {}
container2:
image: alpine:3.16
container_name: container2
cap_add:
- NET_ADMIN
command: >
sh -c "ip route del default && ip route add default via 192.168.0.254 && sleep infinity"
networks:
private_net: {}
networks:
global_net:
driver: bridge
ipam:
config:
- subnet: 172.16.0.0/16
private_net:
driver: bridge
ipam:
config:
- subnet: 192.168.0.0/24おわりに
今回はDockerを用いてプライベートネットワークを構築しました。
今回の記事を書くにあたって調べものをしている最中にサブネットやパケットフィルタリング、ルーティングプロトコルなどさらに興味が湧いてきたので内容が固まったら書こうかと思います。
おまけ
--internalオプションについて
dockerでネットワークを作成する際、--internalというオプションを付けることができる。
$ docker network create --internal --subnet=192.168.0.0/24 private_netこれは、仮想ブリッジを作らずにネットワークを作成するため、外部ネットワークとの通信が不可になる。
プラスして、コンテナ自体にパケットフィルタリングか何かが加えられている模様。
global_net内のcontainer1のiptablesで確認した際にも以下のようなルールが設けられていた。
31 2137 DOCKER_POSTROUTING all -- any any anywhere 127.0.0.11private_netの方は確認していないがそちらも恐らく何らかの設定が加えられている。
取り除こうと思って取り除けるものなのかもわからないので今回は仮想ブリッジを分離する方向で進めた。